python+playwright 设置window.navigator.webdriver属性为false 跳过网站反爬检测
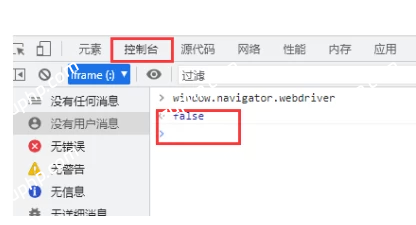
人工正常打开的浏览器 window.navigator.webdriver属性 为false
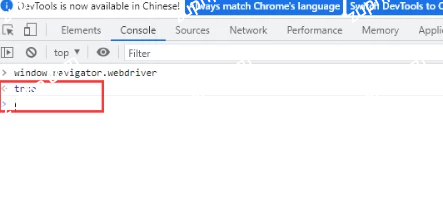
以下是通过playwright 打开的浏览器窗口,查看window.navigator.webdriver属性 为true
跳过反爬检测机制
在启动浏览器时添加以下配置项
import time
from bs4 import BeautifulSoup
from playwright.sync_api import Playwright, sync_playwright, expect
start_time = time.perf_counter()
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch_persistent_context(headless=False,
# 指定本机用户缓存地址
user_data_dir="D:\\chrome_userx\\zuphp",
# 接收下载事件
accept_downloads=True,
bypass_csp=True,
slow_mo=90,
channel="chrome",
args=['--disable-blink-features=AutomationControlled']
)
page = browser.new_page()
page.goto(
"http://www.com")
time.sleep(1) # 根据需要调整等待时间
html = page.content()
print(html)
browser.close()
with sync_playwright() as playwright:
run(playwright)
end_time = time.perf_counter()
print(f'运行时间:{end_time - start_time:.2f}秒')headless=False:以非无头模式启动浏览器,即浏览器界面可见。user_data_dir="D:\\chrome_userx\\zuphp":指定浏览器的用户数据目录,可以用于保存浏览器状态。accept_downloads=True:允许自动下载文件。bypass_csp=True:绕过内容安全策略。slow_mo=90:在操作之间添加 90 毫秒的延迟,有助于观察自动化操作。channel="chrome":使用 Chrome 浏览器。args=['--disable-blink-features=AutomationControlled']:设置浏览器参数,尝试隐藏自动化痕迹。
THE END